前言:其實...這個在九月底就寫好了,只是...要放上Chorme套件平台,需要申請帳號並且要刷5塊美金,
因為沒有信用卡可刷,就這樣放置到現在...Orz
簡介:自己本身還蠻常逛nico動畫的,所以就趁閒暇的時候寫了一個搜尋工具。
套件名稱:Nico Instant (暫定)
下載點:https://sites.google.com/site/kilfu0701b/nico-instant/nico_instant.crx?attredirects=0&d=1
http://goo.gl/xrGnM
使用介紹:
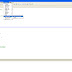
1. 基本上,安裝完成後會看到一個圖示,點圖示後會出現一個popup頁面(如下圖),
這時候可以輸入你要搜尋影片的關鍵字...

2. 人氣標籤功能:當時只有寫search功能,但是...,當腦內一片空白的時候,
連我自己也不知道要找什麼影片...(飛踢)。所以,就在左上角寫了一個小工具,
可以找找人氣標籤。若找不到想要的名稱,可以點"人氣標籤"左鍵一下,
會隨機抓取其他的名稱,或是直接"查看更多"。

3. 一般使用:預設是關鍵字去搜尋,直接輸入要找的關鍵字,下面就會出現搜尋的結果。

4. 其他功能:其實可以用"關鍵字"或"標籤"去搜尋。然後,也有其他選項可排序,
比如最新評論、上傳、撥放次數等等。

5. 若想保留剛剛的搜尋結果,不妨把頁面開到新的視窗吧。

誰適合使用此套件:
經常逛nico、看nico影片的人
誰不適合使用此套件:
嗯?? Nico是甚麼?好吃嗎?(誤很大)
其他:如果有任何使用問題,歡迎回報錯誤。
若有其他想要的附加功能,也可推薦一下。
PS:目前作者轉戰Python BBS開發中,有想到其他功能再補上去!



![[Chrome] Nico Download Manager (nicoDLM)](http://1.bp.blogspot.com/-UWDXWr860BQ/UNHzbyFK08I/AAAAAAAAEDA/lELyd_rCNco/s72-c/1.jpg)
![[聖地巡禮] 長騎美眉 第三話 (ろんぐらいだぁす!)](https://3.bp.blogspot.com/-X4znYbWaaMM/WEoqLIqstwI/AAAAAAAAFe0/JxzXeTGNZMUOVMu_xNZmcJOOwz9NHOD-QCEw/s72-c/08yGBDV.jpg)
![[聖地巡禮] 長騎美眉 第一話 (ろんぐらいだぁす!)](https://3.bp.blogspot.com/-lU8dikGwiyc/WE30PK1IGII/AAAAAAAAFfY/1Cdq1lq0xLcvvNTMq0euqCOGBFvzrt5dACLcB/s72-c/a1.jpg)
![[聖地巡禮] 長騎美眉 第五話 (ろんぐらいだぁす!)](https://4.bp.blogspot.com/-7vC8WxDHR8E/WGsO-aTG0GI/AAAAAAAAFmU/3m-mbJ0v7asm8j0e9ZGVXb2Uwn-zQtodwCLcB/s72-c/111.jpg)
![[聖地巡禮] 長騎美眉 第四話 (ろんぐらいだぁす!)](https://1.bp.blogspot.com/-8lj4v67m8lE/WFOZZhuawJI/AAAAAAAAFfw/NXmjNgAo3dM4XOLIysXF4M8toRPge_S3gCLcB/s72-c/wdGX56M.jpg)
![[聖地巡禮] 長騎美眉 第二話 (ろんぐらいだぁす!)](https://2.bp.blogspot.com/-DiqpsKF7g9o/WEp6kg4L_mI/AAAAAAAAFfE/8gEJBWmqlioyEZCxOQnnDIMZhywGu6HGwCLcB/s72-c/4janhW3.jpg)